重新认识《面向对象 - 六大基本原则》
很多Android源码的实现都有设计模式的影子,对于很多从事Android开发的读者来说,学习Android源码的最大障碍往往是对其设计思想的理解而非源码本身,很多时候我们能看懂一段源码但却不明白其思想,看懂的是这一段源码的实现逻辑而不懂的则是为什么逻辑会是这样,对于开发者来说,知其然却又不知其所以然往往是进阶中最大的阻力。
# 优化代码的第一步 - 单一职责原则
单一职责原则的英文名称是 Single Responsibility Principle,缩写是SRP。SRP的定义是:就一个类而言,应该仅有一个引起它变化的原因。简单来说,一个类中应该是一组相关性很高的函数、数据的封装。就像秦小波老师在《设计模式之禅》中说的:“这是一个备受争议却又及其重要的原则。只要你想和别人争执、怄气或者是吵架,这个原则是屡试不爽的”。因为单一职责的划分界限并不是总是那么清晰,很多时候都是需要靠个人经验来界定。当然,最大的问题就是对职责的定义,什么是类的职责,以及怎么划分类的职责。
我们先来看看下面这一段代码:
/**
* 图片加载类
*/
public class ImageLoader {
// 图片缓存
LruCache<String, Bitmap> mImageCache;
//线程池,线程数量为 CPU 的数量
ExecutorService mExecutorService = Executors.newFixedThreadPool(Runtime.
getRuntime().availableProcessors());
public ImageLoader() {
initImageCache();
}
private void initImageCache() {
//计算可使用的最大内存
final int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
//取四分之一的可用内存作为缓存
final int cacheSize = maxMemory / 4;
mImageCache = new LruCache<String, Bitmap>(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
return bitmap.getRowBytes() * bitmap.getHeight() / 1024;
}
};
}
public void displayImage(final String url, final ImageView imageView) {
imageView.setTag(url);
mExecutorService.submit(new Runnable() {
@Override
public void run() {
Bitmap bitmap = downloadImage(url);
if(bitmap == null) {
return;
}
if(imageView.getTag().equals(url)) {
imageView.setImageBitmap(bitmap);
}
mImageCache.put(url, bitmap);
}
});
}
public Bitmap downloadImage(String imageUrl) {
Bitmap bitmap = null;
try {
URL url = new URL(imageUrl);
final HttpURLConnection conn = (HttpURLConnection) url.openConnection();
bitmap = BitmapFactory.decodeStream(conn.getInputStream());
conn.disconnect();
} catch(Exception e) {
e.printStackTrace();
}
return bitmap;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
这是一个图片加载器,虽然可以实现图片的缓存和显示,但是耦合太严重了,根本没有设计可言,更不要说拓展性、灵活性了。所有的代码都写在一个类里,这样随着功能的增多,ImageLoader类会越来越大,代码也越来越复杂,图片加载系统就越来越脆弱。这时我们就要把ImageLoader拆分一下,把各功能独立出来,让它们满足单一职责原则。
ImageLoader 作出如下修改:
/**
* 图片加载类
*/
public class ImageLoader {
// 图片缓存
ImageCache mImageCache = new ImageCache();
//线程池,线程数量为 CPU 的数量
ExecutorService mExecutorService = Executors.newFixedThreadPool(Runtime.
getRuntime().availableProcessors());
//加载图片
public void displayImage(final String url, final ImageView imageView) {
Bitmap bitmap = mImageCache.get(url);
if(bitmap != null) {
imageView.setImageBitmap(bitmap);
return;
}
imageView.setTag(url);
mExecutorService.submit(new Runnable() {
@Override
public void run() {
Bitmap bitmap = downloadImage(url);
if(bitmap == null) {
return;
}
if(imageView.getTag().equals(url)) {
imageView.setImageBitmap(bitmap);
}
mImageCache.put(url, bitmap);
}
});
}
public Bitmap downloadImage(String imageUrl) {
Bitmap bitmap = null;
try {
URL url = new URL(imageUrl);
final HttpURLConnection conn = (HttpURLConnection) url.openConnection();
bitmap = BitmapFactory.decodeStream(conn.getInputStream());
conn.disconnect();
} catch(Exception e) {
e.printStackTrace();
}
return bitmap;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
并且添加了一个ImageCache类用于处理图片缓存,具体代码如下:
public class ImageCache {
//图片LRU缓存
LruCache<String, Bitmap> mImageCache;
public ImageCache() {
initImageCache();
}
private void initImageCache() {
//计算可使用的最大内存
final int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
//取四分之一的可用内存作为缓存
final int cacheSize = maxMemory / 4;
mImageCache = new LruCache<String, Bitmap>(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap bitmap) {
return bitmap.getRowBytes() * bitmap.getHeight() / 1024;
}
};
}
public void put(String url, Bitmap bitmap) {
mImageCache.put(url, bitmap);
}
public Bitmap get(String url) {
return mImageCache.get(url);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
将ImageLoader一拆为二,ImageLoader只负责图片加载的逻辑,而ImageCache只负责处理图片缓存的逻辑,这样ImageLoader的代码量就变少了,职责也清晰了;当与缓存相关的逻辑需要改变时,不需要修改ImageLoader类,而图片加载的逻辑需要改变时也不会影响到缓存处理的逻辑。
单一职责所表达的泳衣就是“单一”二字。正如上文所说,如何划分一个类,一个函数的职责,每个人都有自己的看法,这需要根据个人经验,具体的业务逻辑而定。但是,它也有一些基本的指导原则,例如,两个完全不一样的功能就不应该放在一个类中。一个类中应该是一组相关性很高的函数、数据的封装。工程师可以不断地审视自己的代码,根据具体的业务、功能对类进行相对应的拆分,这是程序员优化代码迈出的第一步。
# 让程序更稳定、更灵活 - 开闭原则
开闭原则的英文全称是Open Close Principle,简称OCP,它是Java世界里最基础的设计原则,它指导我们如何建立一个稳定的、灵活的系统。开闭原则的定义是:软件中的对象(类、模块、函数等)应该对于扩展是开放的,但是,对于修改是封闭的。在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会将错误引入原本已经经过测试的旧代码中,破坏原有系统。因此,当软件需要变化时,我们应该尽量通过扩展的方式来实现变化,而不是通过修改已有的代码来实现。当然,在现实开发中,只通过继承的方式来升级、维护原有系统只是一个理想化的愿景,因此,在实际的开发过程中,修改原有代码、扩展代码往往是同时存在的。
软件开发过程中,最不会变化的就是变化本身。产品需要不断地升级、维护,没有一个产品从第一版本开发完就再没有变化了,除非在下个版本诞生之前它已经被终止。而产品需要升级,修改原来的代码就可能会引发其他的问题。那么如何确保原有软件模块的正确性,以及尽量少地影响原有模块,答案就是尽量遵守本章要讲述的开闭原则。
还是上面那个例子,重构之后的ImageLoader职责单一,结构清晰。但是有些问题也暴露了出来,我们通过了内存缓存解决了每次从网络加载图片的问题,但是,Android应用的内存很有限,且具有易失性,即当应用重新启动之后,原来已经加载过的图片将会丢失,这样重启之后就需要重新下载!这又会导致加载缓慢,耗费用户流量的问题。我们可以考虑引入SD卡缓存,这样下载过的图片就会缓存到本地,即使重启应用也不需要重新下载了。
新增DiskCache.java 类,将图片缓存到SD卡中:
public class DiskCache {
static String cacheDir = "sdcard/cache/";
//从缓存中获取图片
public Bitmap get(String url) {
return BitmapFactory.decodeFile(cacheDir + url);
}
//将图片缓存到内存中
public void put(String url, Bitmap bmp) {
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = new FileOutputStream(cacheDir + url);
bmp.compress(CompressFormat.PNG, 100, fileOutputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if(fileOutputStream != null) {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
因为需要将图片缓存到SD卡中,所以,ImageLoader代码有所修改,具体代码如下:
public class ImageLoader {
//内存缓存
ImageCache mImageCache = new ImageCache();
//SD卡缓存
DiskCache mDiskCache = new DiskCache();
//是否使用SD卡缓存
boolean isUseDiskCache = false;
//线程池,线程数量为 CPU 的数量
ExecutorService mExecutorService = Executors.newFixedThreadPool(Runtime.
getRuntime().availableProcessors());
public void displayImage(final String url, final ImageView imageView) {
//判断使用哪种缓存
Bitmap bitmap = isUseDiskCache ? mDiskCache.get(url) : mImageCache.get(url);
if(bitmap != null) {
imageView.setImageBitmap(bitmap);
return;
}
//没有缓存,则提交给线程池进行下载
}
public void useDiskCache(boolean useDiskCache) {
isUseDiskCache = useDiskCache;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
从上述代码中可以看到,仅仅新增了一个DiskCache类和往ImageLoader类中加入了少量代码就添加了SD卡缓存功能,用户可以通过useDiskCache方法来对使用哪种缓存进行设置,例如:
ImageLoader imageLoader = new ImageLoader();
//使用 SD卡 缓存
imageLoader.useDiskCache(true);
//使用 内存 缓存
imageLoader.useDiskCache(false);
2
3
4
5
通过 useDiskCache 方法让用户设置不同的缓存,看起来非常方便!但是有些明显的问题,就是使用内存缓存时用户就不能使用SD卡缓存。类似的,使用SD卡缓存时用户就不能使用内存缓存。用户需要这两种策略的综合,首先缓存优先使用内存缓存,如果内存缓存里没有图片再使用SD卡缓存,如果SD卡中也没有图片最后才从网络上获取,这才是最好的缓存策略。
我们新建一个双缓存类 DoubleCache , 具体代码如下:
/**
* 双缓存,获取图片时先从内存缓存中获取,如果内存中没有缓存该图片,再从SD卡中获取。
* 缓存图片也是在内存和SD卡中都缓存一份
*/
public class DoubleCache {
ImageCache mMemoryCache = new ImageCache();
DiskCache mDiskCache = new DiskCache();
//先从内存缓存中获取图片,如果没有,再从 SD 卡中获取
public Bitmap get(String url) {
Bitmap bitmap = mMemoryCache.get(url);
if(bitmap == null) {
bitmap = mDiskCache.get(url);
}
return bitmap;
}
//将图片缓存到内存和SD卡中
public void put(String url, Bitmap bmp) {
mMemoryCache.put(url, bmp);
mDiskCache.put(url, bmp);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
我们再看看最新的ImageLoader类, 代码更新也不多:
public class ImageLoader {
//内存缓存
ImageCache mImageCache = new ImageCache();
//SD卡缓存
DiskCache mDiskCache = new DiskCache();
//双缓存
DoubleCache mDoubleCache = new DoubleCache();
//是否使用SD卡缓存
boolean isUseDiskCache = false;
//是否使用双缓存
boolean isUseDoubleCache = false;
//线程池,线程数量为 CPU 的数量
ExecutorService mExecutorService = Executors.newFixedThreadPool(Runtime.
getRuntime().availableProcessors());
public void displayImage(final String url, final ImageView imageView) {
Bitmap bmp = null;
if (isUseDoubleCache) {
bmp = mDoubleCache.get(url);
} else if(isUseDiskCache) {
bmp = mDiskCache.get(url);
} else {
bmp = mImageCache.get(url);
}
if(bitmap != null) {
imageView.setImageBitmap(bitmap);
return;
}
//没有缓存,则提交给线程池进行下载
}
public void useDiskCache(boolean useDiskCache) {
isUseDiskCache = useDiskCache;
}
public void useDoubleCache(boolean useDoubleCache) {
isUseDoubleCache = useDoubleCache;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
上面这么写还有什么问题吗?我们来分析一下。每次在程序中加入新的缓存实现时都需要修改ImageLoader类,然后通过一个布尔变量来让用户选择使用哪种缓存,因此,就使得在ImageLoader中存在各种if-else判断语句,通过这些判断来确定使用哪种缓存。随着这些逻辑的引入,代码变得越来越复杂、脆弱,如果一不小心写错了某个if条件(条件太多,这是很容易出现的),那就需要更多的时间来排除,整个ImageLoader类也会变得越来越臃肿。最重要的是,用户不能自己实现缓存注入到ImageLoader中,可扩展性差。可扩展性可是框架的最重要特性之一。
软件中的对象(类、模块、函数等)应该对于扩展是开放的,但是对于修改是封闭的,这就是开发-关闭原则。也就是说,当软件需要变化时,我们应该尽量通过扩展的方式来实现变化,而不是通过修改已有的代码来实现。
图1-2:
把ImageLoader再一次进行重构,具体代码如下:
/**
* 图片加载类
*/
public class ImageLoader {
// 图片缓存
ImageCache mImageCache = new MemoryCache();
//线程池,线程数量为 CPU 的数量
ExecutorService mExecutorService = Executors.newFixedThreadPool(Runtime.
getRuntime().availableProcessors());
//注入缓存实现
public void setImageCache(imageCache cache) {
mImageCache = cache;
}
//加载图片
public void displayImage(final String imageUrl, final ImageView imageView) {
Bitmap bitmap = mImageCache.get(imageUrl);
if(bitmap != null) {
imageView.setImageBitmap(bitmap);
return;
}
//图片没缓存,提交到线程池中下载图片
submitLoadRequest(imageUrl, imageView);
}
public void submitLoadRequest(final String imageUrl, final ImageView imageView) {
imageView.setTag(imageUrl);
mExecutorService.submit(new Runnable() {
@Override
public void run() {
Bitmap bitmap = downloadImage(imageUrl);
if(bitmap == null) {
return;
}
if(imageView.getTag().equals(imageUrl)) {
imageView.setImageBitmap(bitmap);
}
mImageCache.put(imageUrl, bitmap);
}
});
}
public Bitmap downloadImage(String imageUrl) {
Bitmap bitmap = null;
try {
URL url = new URL(imageUrl);
final HttpURLConnection conn = (HttpURLConnection) url.openConnection();
bitmap = BitmapFactory.decodeStream(conn.getInputStream());
conn.disconnect();
} catch(Exception e) {
e.printStackTrace();
}
return bitmap;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
经过这次重构,没有了那么多的if-else语句,没有了各种各样的换粗实现对象、布尔变量,代码更加清晰、简单。需要注意的是,这里的ImageCache类并不是原来的那个ImageCache,这次重构程序,我们把它提取成一个图片缓存的接口,用户抽象图片缓存的功能,我们看看这个接口的声明:
public interface ImageCache {
public Bitmap get(String url);
public void put(String url, Bitmap bmp);
}
2
3
4
ImageCache 接口简单定义了获取、缓存图片两个函数,缓存的key是图片的url,值是图片本身。内存缓存、SD卡缓存、双缓存都实现了该接口,我们看看这这几个缓存实现:
//内存缓存MemoryCache 类
public class MemoryCache implements ImageCache {
private LruCache<String, Bitmap> mMemoryCache;
public MemoryCache() {
//初始化LRU缓存
}
@Override
public Bitmap get(String url) {
return mMemoryCache.get(url);
}
@Override
public void put(String url, Bitmap bmp) {
mMemoryCache.put(url, bmp);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//SD卡缓存DiskCache 类
public class DiskCache implements ImageCache {
@Override
public Bitmap get(String url) {
//从本地文件中获取该图片
return null;
}
@Override
public void put(String url, Bitmap bmp) {
//将Bitmap 写入文件中
}
}
2
3
4
5
6
7
8
9
10
11
12
13
//双缓存 DoubleCache 类
public class DoubleCache implements ImageCache {
ImageCache mMemoryCache = new MemoryCache();
ImageCache mDiskCache = new DiskCache();
//先从内存缓存中获取图片,如果没有,再从SD卡中获取
public Bitmap get(String url) {
Bitmap bitmap = mMemoryCache.get(url);
if(bitmap == null) {
bitmap = mDiskCache.get(url);
}
return bitmap;
}
public void put(String url, Bitmap bmp) {
mMemoryCache.put(url, bmp);
mDiskCache.put(url, bmp);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
细心的读者可能注意到了,ImageLoader 类中增加了一个setImageCache(ImageCache cache)函数,用户可以通过该函数设置缓存实现,也就是通常说的依赖注入。下面就看看用户是如何设置缓存实现的:
ImageLoader imageLoader = new ImageLoader();
//使用内存缓存
imageLoader.setImageCache(new MemoryCache());
//使用SD卡缓存
imageLoader.setImageCache(new DiskCache());
//使用双缓存
imageLoader.setImageCache(new DoubleCache());
//使用自定义的图片缓存实现
imageLoader.setImageCache(new ImageCache() {
@Override
public Bitmap get(String url) {
//从缓存中获取图片
return null;
}
@Override
public void put(String url, Bitmap bmp) {
//将Bitmap 写入缓存
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在上述代码中,通过setImageCache(ImageCache cache)方法注入不同的缓存实现,这样不仅能够使ImageLoader更简单、健壮,也使得ImageLoader的可扩展性、灵活性更高。MemoryCache、DiskCache、DoubleCache缓存图片的具体实现完全不一样,但是,它们的一个特点是都实现了ImageCache接口。当用户需要自定义实现缓存策略时,只需要新建一个实现ImageCache接口的类,然后构造该类的对象,并且通过setImageCache(ImageCache cache)注入到ImageLoader中,这样ImageLoader就实现了变化万千的缓存策略,而扩展这些缓存策略并不会导致ImageLoader类的修改。咦!这不就是开闭原则么!“软件中的对象(类、模块、函数等)应该对于扩展是开放的,但是对于修改是封闭的。而遵循开闭原则的重要手段应该是通过抽象……”
开闭原则指导我们,当软件需要变化时,应该尽量通过扩展的方式来实现变化,而不是通过修改已有的代码来实现。这里的“应该尽量”4个字说明OCP原则并不是说绝对不可以修改原始类的,当我们嗅到原来的代码“腐化气味”时,应该尽早地重构,以使得代码恢复到正常的“进化”轨道,而不是通过继承等方式添加新的实现,这会导致类型的膨胀以及历史遗留代码的冗余。我们的开发过程中也没有那么理想化的状况,完全地不用修改原来的代码,因此,在开发过程中需要自己结合具体情况进行考量,是通过修改旧代码还是通过继承使得软件系统更稳定、更灵活,在保证去除“代码腐化”的同时,也保证原有模块的正确性。
# 构建扩展性更好的系统 - 里氏替换原则
里氏替换原则英文全称是Liskov Substitution Principle,简称LSP。它的第一种定义是:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型。上面这种描述确实不太好理解,理论家有时候容易把问题抽象化,本来挺容易理解的事让他们一概括就弄得拗口了。我们再看看另一个直截了当的定义。里氏替换原则第二种定义:所有引用基类的地方必须能透明地使用其子类的对象。
我们知道,面向对象的语言的三大特点是继承、封装、多态,里氏替换原则就是依赖于继承、多态这两大特性。里氏替换原则简单来说就是,所有引用基类的地方必须能透明地使用其子类的对象。通俗点讲,只要父类能出现的地方子类就可以出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。但是,反过来就不行了,有子类出现的地方,父类未必就能适应。说了那么多,其实最终总结就两个字:抽象。
我们先看下图(图1-3)所示:
具体的代码实现:
//窗口类
public class Window {
public void show(View child){
child.draw();
}
}
//建立试图抽象,测量试图的宽高为公用代码,绘制实现交给具体的子类
public abstract class View {
public abstract void draw();
public void measure(int width, int height){
//测量试图大小
}
}
//按钮类的具体实现
public class Button extends View {
public void draw() {
//绘制按钮样式
}
}
//文本类的具体实现
public class TextView extends View {
public void draw() {
//绘制文本样式
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
上述示例中,Window依赖于View,而View定义了一个视图抽象,measure是各个子类共享的方法,子类通过覆写View的draw方法实现具有各自特色的功能,在这里,这个功能就是绘制自身的内容。任何继承自View类的子类都可以设置给show方法,也就我们所说的里氏替换。通过里氏替换,就可以自定义各式各样、千变万化的View,然后传递给Window,Window负责组织View,并且将View显示到屏幕上。 里氏替换原则的核心原理是抽象,抽象又依赖于继承这个特性,在OOP当中,继承的优缺点都相当明显。
优点如下:
- 代码重用,减少创建类的成本,每个子类都拥有父类的方法和属性;
- 子类与父类基本相似,但又与父类有所区别;
- 提高代码的可扩展性。
继承的缺点:
- 继承是侵入性的,只要继承就必须拥有父类的所有属性和方法;
- 可能造成子类代码冗余、灵活性降低,因为子类必须拥有父类的属性和方法。
事物总是具有两面性,如何权衡利与弊都是需要根据具体场景来做出选择并加以处理。里氏替换原则指导我们构建扩展性更好的软件系统,我们还是接着上面的ImageLoader来做说明。
MemoryCache、DiskCache、DoubleCache都可以替换ImageCache的工作,并且能够保证行为的正确性。ImageCache建立了获取缓存图片、保存缓存图片的接口规范,MemoryCache等根据接口规范实现了相应的功能,用户只需要在使用时指定具体的缓存对象就可以动态地替换ImageLoader中的缓存策略。这就使得ImageLoader的缓存系统具有了无线的可能性,也就是保证了可扩展性。
想象一个场景,当ImageLoader中的setImageCache(ImageCache cache)中的cache对象不能够被子类所替换,那么用户如何设置不同的缓存对象以及用户如何自定义自己的缓存实现,通过1.3节中的useDiskCache方法吗?显然不是的,里氏替换原则就为这类问题提供了指导原则,也就是建立抽象,通过抽象建立规范,具体的实现在运行时替换掉抽象,保证系统的高扩展性、灵活性。开闭原则和里氏替换原则往往是生死相依、不弃不离的,通过里氏替换来达到对扩展开放,对修改关闭的效果。然而,这两个原则都同时强调了一个OOP的重要特性——抽象,因此,在开发过程中运用抽象是走向代码优化的重要一步。
# 让项目拥有变化的能力 - 依赖倒置原则
依赖倒置原则英文全称是Dependence Inversion Principle,简称DIP。依赖倒置原则指代了一种特定的解耦形式,使得高层次的模块不依赖于低层次的模块的实现细节的目的,依赖模块被颠倒了。这个概念有点不好理解,这到底是什么意思呢?
依赖倒置原则的几个关键点:
- 高层模块不应该依赖低层模块,两者都应该依赖其抽象;
- 抽象不应该依赖细节;
- 细节应该依赖抽象。
在Java语言中,抽象就是指接口或抽象类,两者都是不能直接被实例化的;细节就是实现类,实现接口或继承抽象类而产生的类就是细节,其特点就是,可以直接被实例化,也就是可以加上一个关键字 new 产生一个对象。高层模块就是调用端,低层模块就是具体实现类。依赖倒置原则在 Java 语言中的表现就是: 模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的。 这又是一个将理论抽象化的实例,其实一句话就可以概括:面向接口编程,或者说是面向抽象编程,这里的抽象指的是接口或者抽象类。面向接口编程是面向对象精髓之一,也就是上面两节强调的抽象。
如果在类与类直接依赖于细节,那么它们之间就有直接的耦合,当具体实现需要变化时,意味着在这要同时修改依赖者的代码,并且限制了系统的可扩展性。我们看图1-3中,ImageLoader直接依赖于MemoryCache,这个MemoryCache是一个具体实现,而不是一个抽象类或者接口。这导致了ImageLoader直接依赖了具体细节,当MemoryCache不能满足ImageLoader而需要被其他缓存实现替换时,此时就必须修改ImageLoader的代码,例如:
public class ImageLoader {
// 内存缓存 ( 直接依赖于细节 )
MemoryCache mMemoryCache = new MemoryCache();
// 加载图片到ImageView中
public void displayImage(String url, ImageView imageView) {
Bitmap bmp = mMemoryCache.get(url);
if (bmp == null) {
downloadImage(url, imageView);
} else {
imageView.setImageBitmap(bmp);
}
}
public void setImageCache(MemoryCache cache) {
mCache = cache ;
}
// 代码省略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
随着产品的升级,用户发现MemoryCache已经不能满足需求,用户需要ImageLoader可以将图片同时缓存到内存和SD卡中,或者可以让用户自定义实现缓存。此时,我们的MemoryCache这个类名不仅不能够表达内存缓存和SD卡缓存的意义,也不能够满足功能。另外,用户需要自定义缓存实现时还必须继承自MemoryCache,而用户的缓存实现可不一定与内存缓存有关,这在命名上的限制也让用户体验不好。重构的时候到了!第一种方案是将MemoryCache修改为DoubleCache,然后在DoubleCache中实现具体的缓存功能。我们需要将ImageLoader修改如下:
public class ImageLoader {
// 双缓存 ( 直接依赖于细节 )
DoubleCache mCache = new DoubleCache();
// 加载图片到ImageView中
public void displayImage(String url, ImageView imageView) {
Bitmap bmp = mCache.get(url);
if (bmp == null) {
// 异步下载图片
downloadImageAsync(url, imageView);
} else {
imageView.setImageBitmap(bmp);
}
}
public void setImageCache(DoubleCache cache) {
mCache = cache ;
}
// 代码省略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
我们将MemoryCache修改成DoubleCache,然后修改了ImageLoader中缓存类的具体实现,轻轻松松就满足了用户需求。等等!这不还是依赖于具体的实现类(DoubleCache)吗?当用户的需求再次变化时,我们又要通过修改缓存实现类和ImageLoader代码来实现?修改原有代码不是违反了1.3节中的开闭原则吗?
当然,这些都是在给出图1-2(1.3节)以及相应的代码之前,既然是这样,那显然后面给出的解决方案就能够让缓存系统更加灵活。一句话概括起来就是:依赖抽象,而不依赖具体实现。针对于图片缓存,建立ImageCache抽象,该抽象中增加了get和put方法用以实现图片的存取。每种缓存实现都必须实现这个接口,并且实现自己的存取方法。当用户需要使用不同的缓存实现时,直接通过依赖注入即可,保证了系统的灵活性。我们再来简单回顾一下相关代码:
ImageCache缓存抽象:
public interface ImageCache {
public Bitmap get(String url);
public void put(String url, Bitmap bmp);
}
2
3
4
ImageLoader类:
public class ImageLoader {
// 图片缓存类,依赖于抽象,并且有一个默认的实现
ImageCache mCache = new MemoryCache();
// 加载图片
public void displayImage(String url, ImageView imageView) {
Bitmap bmp = mCache.get(url);
if (bmp == null) {
// 异步加载图片
downloadImageAsync(url, imageView);
} else {
imageView.setImageBitmap(bmp);
}
}
/**
* 设置缓存策略,依赖于抽象
*/
public void setImageCache(ImageCache cache) {
mCache = cache;
}
// 代码省略
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在这里,我们建立了ImageCache抽象,并且让ImageLoader依赖于抽象而不是具体细节。当需求发生变更时,只需要实现ImageCahce类或者继承其他已有的ImageCache子类完成相应的缓存功能,然后将具体的实现注入到ImageLoader即可实现缓存功能的替换,这就保证了缓存系统的高可扩展性,拥有了拥抱变化的能力,而这一切的基本指导原则就是我们的依赖倒置原则。从上述几节中我们发现,要想让我们的系统更为灵活,抽象似乎成了我们唯一的手段。
# 系统有更高的灵活性 - 接口隔离原则
接口隔离原则英文全称是InterfaceSegregation Principles,简称ISP。它的定义是:客户端不应该依赖它不需要的接口。另一种定义是:类间的依赖关系应该建立在最小的接口上。接口隔离原则将非常庞大、臃肿的接口拆分成为更小的和更具体的接口,这样用户将会只需要知道他们感兴趣的方法。接口隔离原则的目的是系统解开耦合,从而容易重构、更改和重新部署。
接口隔离原则说白了就是,让客户端依赖的接口尽可能地小,这样说可能还是有点抽象,我们还是以一个示例来说明一下。在此之前我们来说一个场景,在Java 6以及之前的JDK版本,有一个非常讨厌的问题,那就是在使用了OutputStream或者其他可关闭的对象之后,我们必须保证它们最终被关闭了,我们的SD卡缓存类中就有这样的代码:
// 将图片缓存到内存中
public void put(String url, Bitmap bmp) {
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = new FileOutputStream(cacheDir + url);
bmp.compress(CompressFormat.PNG, 100, fileOutputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (fileOutputStream != null) {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
} // end if
} // end if finally
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我们看到的这段代码可读性非常差,各种try…catch嵌套,都是些简单的代码,但是会严重影响代码的可读性,并且多层级的大括号很容易将代码写到错误的层级中。大家应该对这类代码也非常反感,那我们看看如何解决这类问题。
我们知道Java中有一个Closeable接口,该接口标识了一个可关闭的对象,它只有一个close方法,如图1-4所示。
我们要讲的FileOutputStream类就实现了这个接口,我们从图1-4中可以看到,还有一百多个类实现了Closeable这个接口,这意味着,在关闭这一百多个类型的对象时,都需要写出像put方法中finally代码段那样的代码。这不能忍,既然都是实现了Closeable接口,那只要我建一个方法统一来关闭这些对象不就可以了么?
图1-4:
public final class CloseUtils {
private CloseUtils() { }
/**
* 关闭Closeable对象
* @param closeable
*/
public static void closeQuietly(Closeable closeable) {
if (null != closeable) {
try {
closeable.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
我们再看看把这段代码运用到上述的put方法中的效果如何:
public void put(String url, Bitmap bmp) {
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = new FileOutputStream(cacheDir + url);
bmp.compress(CompressFormat.PNG, 100, fileOutputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
CloseUtils.closeQuietly(fileOutputStream);
}
}
2
3
4
5
6
7
8
9
10
11
代码简洁了很多!而且这个closeQuietly方法可以运用到各类可关闭的对象中,保证了代码的重用性。CloseUtils的closeQuietly方法的基本原理就是依赖于Closeable抽象而不是具体实现(这不是1.4节中的依赖倒置原则么),并且建立在最小化依赖原则的基础,它只需要知道这个对象是可关闭,其他的一概不关心,也就是这里的接口隔离原则。
试想一下,如果在只是需要关闭一个对象时,它却暴露出了其他的接口函数,比如OutputStream的write方法,这就使得更多的细节暴露在客户端代码面前,不仅没有很好地隐藏实现,还增加了接口的使用难度。而通过Closeable接口将可关闭的对象抽象起来,这样只需要客户端依赖于Closeable就可以对客户端隐藏其他的接口信息,客户端代码只需要知道这个对象可关闭(只可调用close方法)即可。ImageLoader中的ImageCache就是接口隔离原则的运用,ImageLoader只需要知道该缓存对象有存、取缓存图片的接口即可,其他的一概不管,这就使得缓存功能的具体实现对ImageLoader具体的隐藏。这就是用最小化接口隔离了实现类的细节,也促使我们将庞大的接口拆分到更细粒度的接口当中,这使得我们的系统具有更低的耦合性,更高的灵活性。
Bob大叔(Robert C Martin)在21世纪早期将 单一职责 、 开闭原则 、 里氏替换 、 接口隔离 以及 依赖倒置(也称为依赖反转) 5个原则定义为SOLID原则,指代了面向对象编程的5个基本原则。当这些原则被一起应用时,它们使得一个软件系统更清晰、简单、最大程度地拥抱变化。SOLID被典型地应用在测试驱动开发上,并且是敏捷开发以及自适应软件开发基本原则的重要组成部分。在经过第1.1~1.5节的学习之后,我们发现这几大原则最终就可以化为这几个关键词:抽象、单一职责、最小化。那么在实际开发过程中如何权衡、实践这些原则,是大家需要在实践中多思考与领悟,正所谓”学而不思则罔,思而不学则殆”,只有不断地学习、实践、思考,才能够在积累的过程有一个质的飞越。
# 更好的可扩展性 - 迪米特原则
迪米特原则英文全称为Law of Demeter,简称LOD,也称为最少知识原则(Least Knowledge Principle)。虽然名字不同,但描述的是同一个原则:一个对象应该对其他对象有最少的了解。通俗地讲,一个类应该对自己需要耦合或调用的类知道得最少,类的内部如何实现、如何复杂都与调用者或者依赖者没关系,调用者或者依赖者只需要知道他需要的方法即可,其他的我一概不关心。类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
迪米特法则还有一个英文解释是:Only talk to your immedate friends,翻译过来就是:只与直接的朋友通信。什么叫做直接的朋友呢?每个对象都必然会与其他对象有耦合关系,两个对象之间的耦合就成为朋友关系,这种关系的类型有很多,例如组合、聚合、依赖等。
光说不练很抽象呐,下面我们就以租房为例来讲讲迪米特原则。 “北漂”的同学比较了解,在北京租房绝大多数都是通过中介找房。我们设定的情境为:我只要求房间的面积和租金,其他的一概不管,中介将符合我要求的房子提供给我就可以。下面我们看看这个示例:
/**
* 房间
*/
public class Room {
public float area;
public float price;
public Room(float area, float price) {
this.area = area;
this.price = price;
}
@Override
public String toString() {
return "Room [area=" + area + ", price=" + price + "]";
}
}
/**
* 中介
*/
public class Mediator {
List<Room> mRooms = new ArrayList<Room>();
public Mediator() {
for (inti = 0; i < 5; i++) {
mRooms.add(new Room(14 + i, (14 + i) * 150));
}
}
public List<Room>getAllRooms() {
return mRooms;
}
}
/**
* 租户
*/
public class Tenant {
public float roomArea;
public float roomPrice;
public static final float diffPrice = 100.0001f;
public static final float diffArea = 0.00001f;
public void rentRoom(Mediator mediator) {
List<Room>rooms = mediator.getAllRooms();
for (Room room : rooms) {
if (isSuitable(room)) {
System.out.println("租到房间啦! " + room);
break;
}
}
}
private boolean isSuitable(Room room) {
return Math.abs(room.price - roomPrice) < diffPrice
&&Math.abs(room.area - roomArea) < diffArea;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
从上面的代码中可以看到,Tenant不仅依赖了Mediator类,还需要频繁地与Room类打交道。租户类的要求只是通过中介找到一间适合自己的房间罢了,如果把这些检测条件都放在Tenant类中,那么中介类的功能就被弱化,而且导致Tenant与Room的耦合较高,因为Tenant必须知道许多关于Room的细节。当Room变化时Tenant也必须跟着变化。Tenant又与Mediator耦合,就导致了纠缠不清的关系。这个时候就需要我们分清谁才是我们真正的“朋友”,在我们所设定的情况下,显然是Mediator(虽然现实生活中不是这样的)。上述代码的结构如图1-5所示。
图1-5:
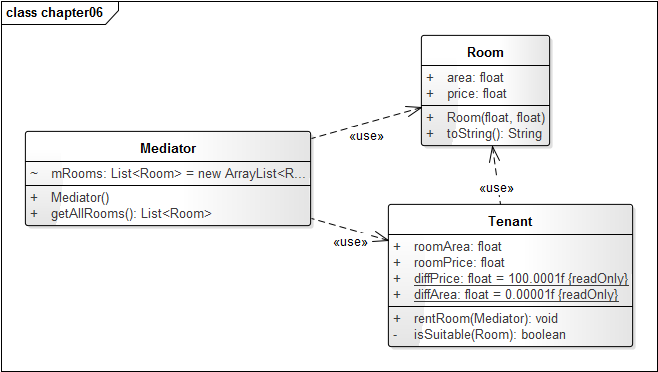
既然是耦合太严重,那我们就只能解耦了,首先要明确地是,我们只和我们的朋友通信,这里就是指Mediator对象。必须将Room相关的操作从Tenant中移除,而这些操作案例应该属于Mediator,我们进行如下重构:
/**
* 中介
*/
public class Mediator {
List<Room> mRooms = new ArrayList<Room>();
public Mediator() {
for (inti = 0; i < 5; i++) {
mRooms.add(new Room(14 + i, (14 + i) * 150));
}
}
public Room rentOut(float area, float price) {
for (Room room : mRooms) {
if (isSuitable(area, price, room)) {
return room;
}
}
return null;
}
private boolean isSuitable(float area, float price, Room room) {
return Math.abs(room.price - price) < Tenant.diffPrice
&& Math.abs(room.area - area) < Tenant.diffPrice;
}
}
/**
* 租户
*/
public class Tenant {
public float roomArea;
public float roomPrice;
public static final float diffPrice = 100.0001f;
public static final float diffArea = 0.00001f;
public void rentRoom(Mediator mediator) {
System.out.println("租到房啦 " + mediator.rentOut(roomArea, roomPrice));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
重构后的结构图如图1-6所示。
图1-6:
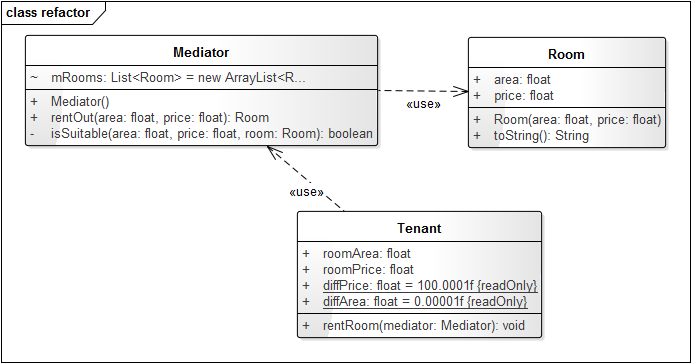
只是将对于Room的判定操作移到了Mediator类中,这本应该是Mediator的职责,他们根据租户设定的条件查找符合要求的房子,并且将结果交给租户就可以了。租户并不需要知道太多关于Room的细节,比如与房东签合同、房东的房产证是不是真的、房内的设施坏了之后我要找谁维修等,当我们通过我们的“朋友”中介租了房之后,所有的事情我们都通过与中介沟通就好了,房东、维修师傅等这些角色并不是我们直接的“朋友”。“只与直接的朋友通信”这简单的几个字就能够将我们从乱七八糟的关系网中抽离出来,使我们的耦合度更低、稳定性更好。
就拿sd卡缓存来说吧,ImageCache就是用户的直接朋友,而SD卡缓存内部却是使用了jake wharton的DiskLruCache实现,这个DiskLruCache就不属于用户的直接朋友了,因此,用户完全不需要知道它的存在,用户只需要与ImageCache对象打交道即可。例如将图片存到SD卡中的代码如下。
public void put(String url, Bitmap value) {
DiskLruCache.Editor editor = null;
try {
// 如果没有找到对应的缓存,则准备从网络上请求数据,并写入缓存
editor = mDiskLruCache.edit(url);
if (editor != null) {
OutputStream outputStream = editor.newOutputStream(0);
if (writeBitmapToDisk(value, outputStream)) {
// 写入disk缓存
editor.commit();
} else {
editor.abort();
}
CloseUtils.closeQuietly(outputStream);
}
} catch (IOException e) {
e.printStackTrace();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
用户在使用SD卡缓存时,根本不知晓DiskLruCache的实现,这就很好地对用户隐藏了具体实现。当我们已经“牛”到可以自己完成SD卡的LRU实现时,就可以随心所欲的替换掉jake wharton的DiskLruCache。代码大体如下:
`
@Override
public void put(String url, Bitmap bmp) {
// 将Bitmap写入文件中
FileOutputStream fos = null;
try {
// 构建图片的存储路径 ( 省略了对url取md5)
fos = new FileOutputStream("sdcard/cache/" + imageUrl2MD5(url));
bmp.compress(CompressFormat.JPEG, 100, fos);
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if ( fos != null ) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} // end if finally
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SD卡缓存的具体实现虽然被替换了,但用户根本不会感知到。因为用户根本不知道DiskLruCache的存在,他们没有与DiskLruCache进行通信,他们只认识直接“朋友”ImageCache,ImageCache将一切细节隐藏在了直接“朋友”的外衣之下,使得系统具有更低的耦合性和更好的可扩展性。
# 总结
在应用开发过程中,最难的不是完成应用的开发工作,而是在后续的升级、维护过程中让应用系统能够拥抱变化。拥抱变化也就意味着在满足需求且不破坏系统稳定性的前提下保持高可扩展性、高内聚、低耦合,在经历了各版本的变更之后依然保持清晰、灵活、稳定的系统架构。当然,这是一个比较理想的情况,但我们必须要朝着这个方向去努力,那么遵循面向对象六大原则就是我们走向灵活软件之路所迈出的第一步。
本文为《Android源码设计模式解析与实战》第一章的笔记
